注意
跳到結尾下載完整的範例程式碼。
StandardScaler 的差異¶
StandardScaler 執行非常基礎的縮放。ONNX 中的轉換假設 (x / y) 等同於 x * ( 1 / y),但這在浮點數或雙精度數中並不正確 (請參閱編譯器會將除法最佳化為乘法嗎)。即使差異很小,如果下一步是決策樹,也可能會產生差異。一個小差異,決策就會遵循樹中的另一條路徑。讓我們看看如何解決這個問題。
一個失敗的範例¶
這不是典型的範例,它的建立是基於假設 (x / y) 在電腦上通常與 x * ( 1 / y) 不同。
import onnxruntime
import onnx
import os
import math
import numpy as np
import matplotlib.pyplot as plt
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
from onnxruntime import InferenceSession
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.tree import DecisionTreeRegressor
from skl2onnx.sklapi import CastTransformer
from skl2onnx import to_onnx
奇怪的資料。
X, y = make_regression(10000, 10, random_state=3)
X_train, X_test, y_train, _ = train_test_split(X, y, random_state=3)
Xi_train, yi_train = X_train.copy(), y_train.copy()
Xi_test = X_test.copy()
for i in range(X.shape[1]):
Xi_train[:, i] = (Xi_train[:, i] * math.pi * 2**i).astype(np.int64)
Xi_test[:, i] = (Xi_test[:, i] * math.pi * 2**i).astype(np.int64)
max_depth = 10
Xi_test = Xi_test.astype(np.float32)
簡單的模型。
轉換為 ONNX。
onx1 = to_onnx(model1, X_train[:1].astype(np.float32), target_opset=15)
sess1 = InferenceSession(onx1.SerializeToString(), providers=["CPUExecutionProvider"])
以及最大差異。
322.39065126389346
圖形。
pydot_graph = GetPydotGraph(
onx1.graph,
name=onx1.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("cast1.dot")
os.system("dot -O -Gdpi=300 -Tpng cast1.dot")
image = plt.imread("cast1.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
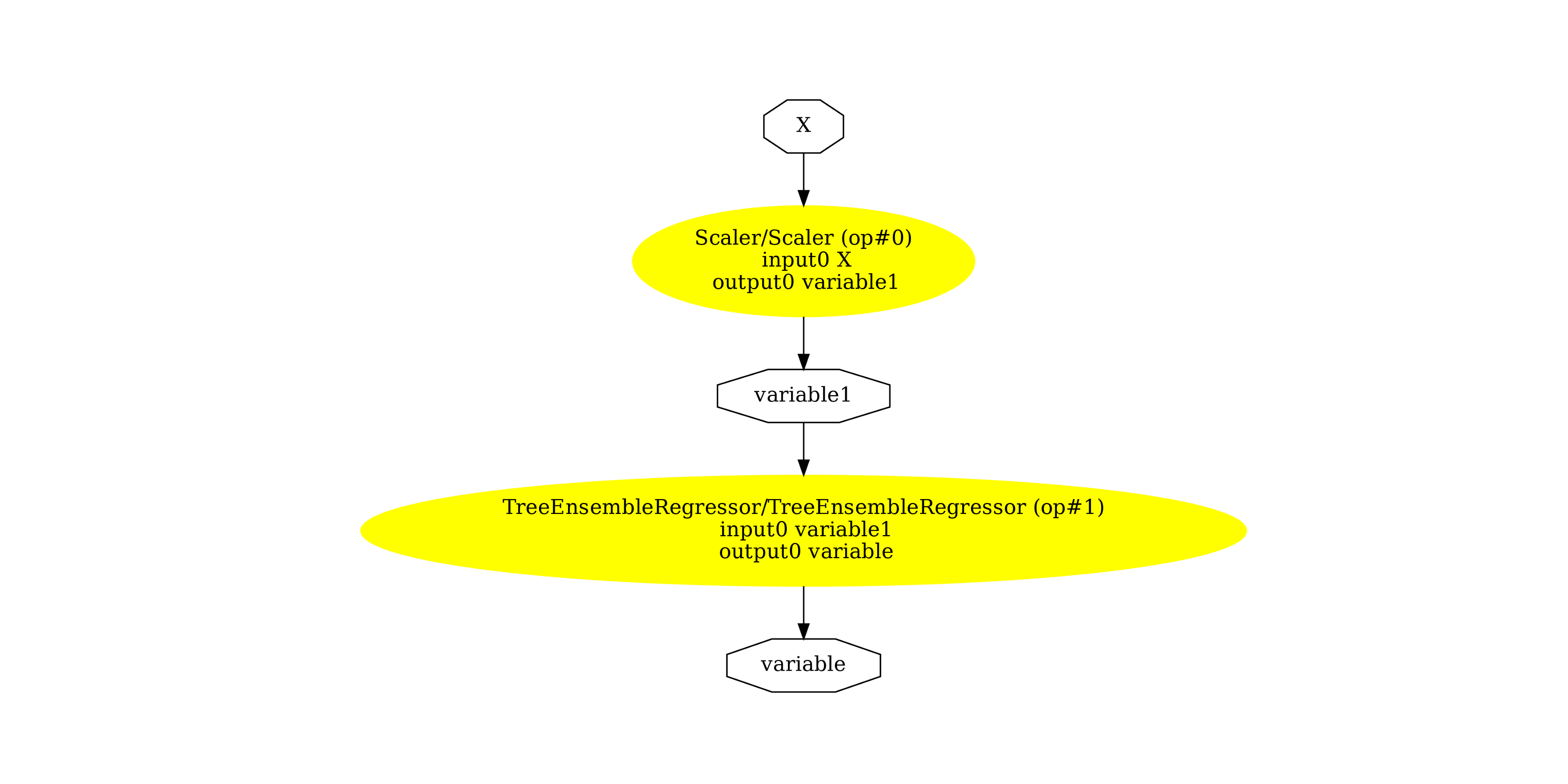
(-0.5, 2536.5, 1707.5, -0.5)
新的管線¶
修正轉換需要將 (x * (1 / y) 替換為 (x / y),而這個除法必須以雙精度進行。預設情況下,sklearn-onnx 假設每個電腦都應以浮點數進行運算。ONNX 1.7 規格 不支援雙精度縮放 (輸入和輸出支援,但參數不支援)。解決方案需要變更轉換 (透過使用選項 ‘div’ 來移除節點 Scaler) 並透過插入明確的 Cast 來使用雙精度。
model2 = Pipeline(
[
("cast64", CastTransformer(dtype=np.float64)),
("scaler", StandardScaler()),
("cast", CastTransformer()),
("dt", DecisionTreeRegressor(max_depth=max_depth)),
]
)
model2.fit(Xi_train, yi_train)
exp2 = model2.predict(Xi_test)
onx2 = to_onnx(
model2,
X_train[:1].astype(np.float32),
options={StandardScaler: {"div": "div_cast"}},
target_opset=15,
)
sess2 = InferenceSession(onx2.SerializeToString(), providers=["CPUExecutionProvider"])
got2 = sess2.run(None, {"X": Xi_test})[0]
md2 = maxdiff(exp2, got2)
print(md2)
2.9884569016758178e-05
圖形。
pydot_graph = GetPydotGraph(
onx2.graph,
name=onx2.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("cast2.dot")
os.system("dot -O -Gdpi=300 -Tpng cast2.dot")
image = plt.imread("cast2.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
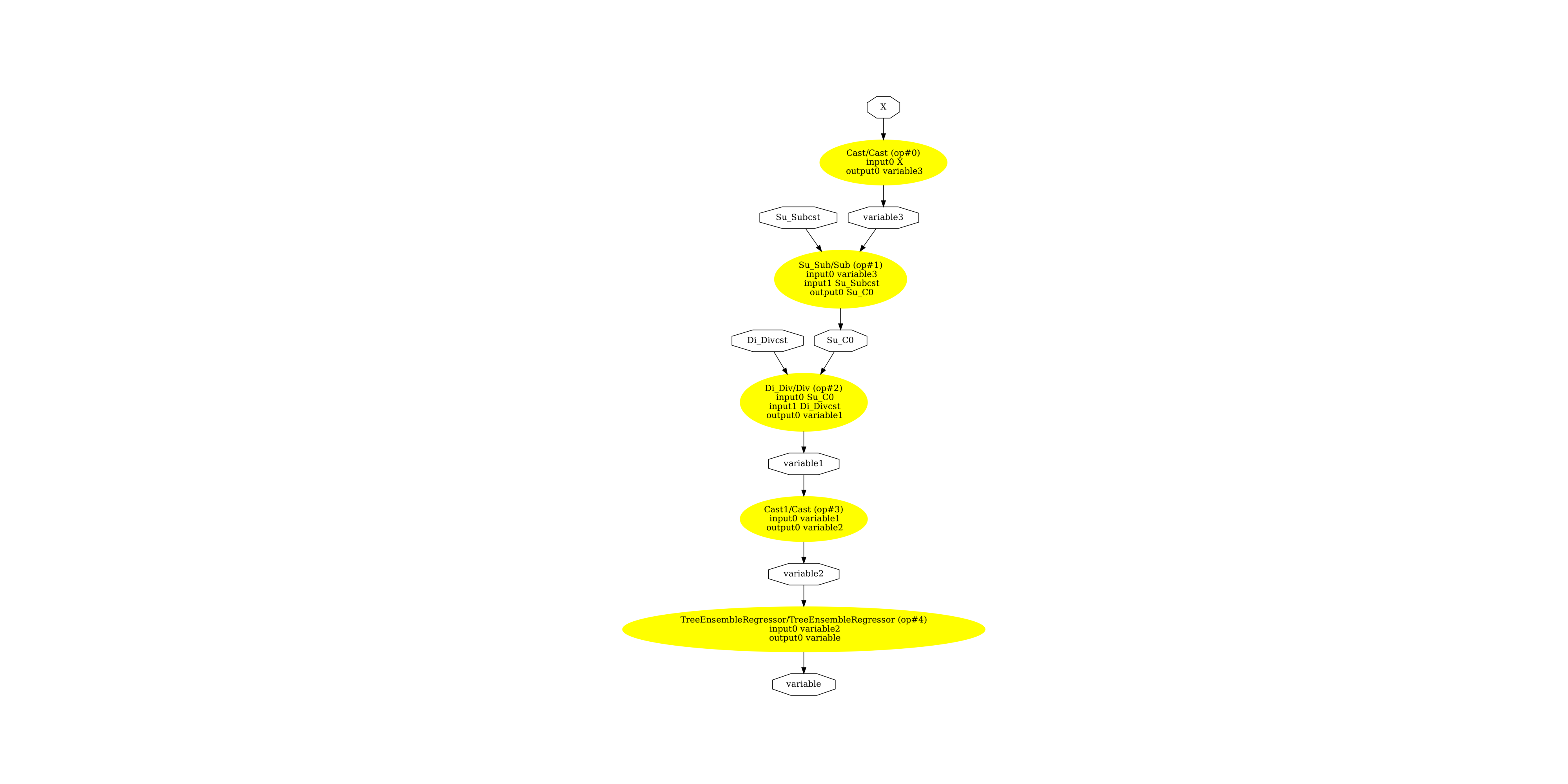
(-0.5, 2536.5, 4171.5, -0.5)
此範例使用的版本
import sklearn # noqa
print("numpy:", np.__version__)
print("scikit-learn:", sklearn.__version__)
import skl2onnx # noqa
print("onnx: ", onnx.__version__)
print("onnxruntime: ", onnxruntime.__version__)
print("skl2onnx: ", skl2onnx.__version__)
numpy: 1.26.4
scikit-learn: 1.6.dev0
onnx: 1.17.0
onnxruntime: 1.18.0+cu118
skl2onnx: 1.17.0
腳本總執行時間:(0 分鐘 4.086 秒)