注意
前往結尾以下載完整的範例程式碼
當自訂模型既非分類器也非迴歸器時¶
scikit-learn 的 API 指定迴歸器產生一個輸出,而分類器產生兩個輸出,預測標籤和機率。此處的目標是新增第三個結果,告知機率是否高於給定的閾值。這是在方法 validate 中實作的。
鳶尾花和評分¶
建立一個新的類別,它訓練任何分類器並實作上述的 validate 方法。
import inspect
import numpy as np
import skl2onnx
import onnx
import sklearn
from sklearn.base import ClassifierMixin, BaseEstimator, clone
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from skl2onnx import update_registered_converter
import os
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
import onnxruntime as rt
from onnxconverter_common.onnx_ops import apply_identity, apply_cast, apply_greater
from skl2onnx import to_onnx, get_model_alias
from skl2onnx.proto import onnx_proto
from skl2onnx.common._registration import get_shape_calculator
from skl2onnx.common.data_types import FloatTensorType, Int64TensorType
import matplotlib.pyplot as plt
class ValidatorClassifier(BaseEstimator, ClassifierMixin):
def __init__(self, estimator=None, threshold=0.75):
ClassifierMixin.__init__(self)
BaseEstimator.__init__(self)
if estimator is None:
estimator = LogisticRegression(solver="liblinear")
self.estimator = estimator
self.threshold = threshold
def fit(self, X, y, sample_weight=None):
sig = inspect.signature(self.estimator.fit)
if "sample_weight" in sig.parameters:
self.estimator_ = clone(self.estimator).fit(
X, y, sample_weight=sample_weight
)
else:
self.estimator_ = clone(self.estimator).fit(X, y)
return self
def predict(self, X):
return self.estimator_.predict(X)
def predict_proba(self, X):
return self.estimator_.predict_proba(X)
def validate(self, X):
pred = self.predict_proba(X)
mx = pred.max(axis=1)
return (mx >= self.threshold) * 1
data = load_iris()
X, y = data.data, data.target
X_train, X_test, y_train, y_test = train_test_split(X, y)
model = ValidatorClassifier()
model.fit(X_train, y_train)
現在讓我們測量指標,該指標指示預測機率是否高於閾值。
print(model.validate(X_test))
[0 0 1 0 0 0 1 0 0 0 0 1 1 0 1 0 0 0 1 0 1 0 1 1 0 1 0 1 1 0 1 0 1 0 0 0 1
1]
轉換為 ONNX¶
新模型的轉換失敗,因為程式庫不知道任何與此新模型相關的轉換器。
try:
to_onnx(model, X_train[:1].astype(np.float32), target_opset=12)
except RuntimeError as e:
print(e)
Unable to find a shape calculator for type '<class '__main__.ValidatorClassifier'>'.
It usually means the pipeline being converted contains a
transformer or a predictor with no corresponding converter
implemented in sklearn-onnx. If the converted is implemented
in another library, you need to register
the converted so that it can be used by sklearn-onnx (function
update_registered_converter). If the model is not yet covered
by sklearn-onnx, you may raise an issue to
https://github.com/onnx/sklearn-onnx/issues
to get the converter implemented or even contribute to the
project. If the model is a custom model, a new converter must
be implemented. Examples can be found in the gallery.
自訂轉換器¶
我們重複使用來自 為您自己的模型撰寫自己的轉換器 的一些程式碼。形狀計算器定義了轉換後模型的每個輸出的形狀。
def validator_classifier_shape_calculator(operator):
input0 = operator.inputs[0] # inputs in ONNX graph
outputs = operator.outputs # outputs in ONNX graph
op = operator.raw_operator # scikit-learn model (mmust be fitted)
if len(outputs) != 3:
raise RuntimeError("3 outputs expected not {}.".format(len(outputs)))
N = input0.type.shape[0] # number of observations
C = op.estimator_.classes_.shape[0] # dimension of outputs
outputs[0].type = Int64TensorType([N]) # label
outputs[1].type = FloatTensorType([N, C]) # probabilities
outputs[2].type = Int64TensorType([C]) # validation
然後是轉換器。
def validator_classifier_converter(scope, operator, container):
outputs = operator.outputs # outputs in ONNX graph
op = operator.raw_operator # scikit-learn model (mmust be fitted)
# We reuse existing converter and declare it
# as a local operator.
model = op.estimator_
alias = get_model_alias(type(model))
val_op = scope.declare_local_operator(alias, model)
val_op.inputs = operator.inputs
# We add an intermediate outputs.
val_label = scope.declare_local_variable("val_label", Int64TensorType())
val_prob = scope.declare_local_variable("val_prob", FloatTensorType())
val_op.outputs.append(val_label)
val_op.outputs.append(val_prob)
# We adjust the output of the submodel.
shape_calc = get_shape_calculator(alias)
shape_calc(val_op)
# We now handle the validation.
val_max = scope.get_unique_variable_name("val_max")
if container.target_opset >= 18:
axis_name = scope.get_unique_variable_name("axis")
container.add_initializer(axis_name, onnx_proto.TensorProto.INT64, [1], [1])
container.add_node(
"ReduceMax",
[val_prob.full_name, axis_name],
val_max,
name=scope.get_unique_operator_name("ReduceMax"),
keepdims=0,
)
else:
container.add_node(
"ReduceMax",
val_prob.full_name,
val_max,
name=scope.get_unique_operator_name("ReduceMax"),
axes=[1],
keepdims=0,
)
th_name = scope.get_unique_variable_name("threshold")
container.add_initializer(
th_name, onnx_proto.TensorProto.FLOAT, [1], [op.threshold]
)
val_bin = scope.get_unique_variable_name("val_bin")
apply_greater(scope, [val_max, th_name], val_bin, container)
val_val = scope.get_unique_variable_name("validate")
apply_cast(scope, val_bin, val_val, container, to=onnx_proto.TensorProto.INT64)
# We finally link the intermediate output to the shared converter.
apply_identity(scope, val_label.full_name, outputs[0].full_name, container)
apply_identity(scope, val_prob.full_name, outputs[1].full_name, container)
apply_identity(scope, val_val, outputs[2].full_name, container)
然後是註冊。
update_registered_converter(
ValidatorClassifier,
"CustomValidatorClassifier",
validator_classifier_shape_calculator,
validator_classifier_converter,
)
還有轉換…
try:
to_onnx(model, X_test[:1].astype(np.float32), target_opset=12)
except RuntimeError as e:
print(e)
3 outputs expected not 2.
它失敗了,因為程式庫預期該模型的行為類似於產生兩個輸出的分類器。我們需要新增自訂解析器來告知程式庫此模型產生三個輸出。
自訂解析器¶
def validator_classifier_parser(scope, model, inputs, custom_parsers=None):
alias = get_model_alias(type(model))
this_operator = scope.declare_local_operator(alias, model)
# inputs
this_operator.inputs.append(inputs[0])
# outputs
val_label = scope.declare_local_variable("val_label", Int64TensorType())
val_prob = scope.declare_local_variable("val_prob", FloatTensorType())
val_val = scope.declare_local_variable("val_val", Int64TensorType())
this_operator.outputs.append(val_label)
this_operator.outputs.append(val_prob)
this_operator.outputs.append(val_val)
# end
return this_operator.outputs
註冊。
update_registered_converter(
ValidatorClassifier,
"CustomValidatorClassifier",
validator_classifier_shape_calculator,
validator_classifier_converter,
parser=validator_classifier_parser,
)
再次轉換。
model_onnx = to_onnx(model, X_test[:1].astype(np.float32), target_opset=12)
最終測試¶
現在我們需要檢查 ONNX 的結果是否相同。
X32 = X_test[:5].astype(np.float32)
sess = rt.InferenceSession(
model_onnx.SerializeToString(), providers=["CPUExecutionProvider"]
)
results = sess.run(None, {"X": X32})
print("--labels--")
print("sklearn", model.predict(X32))
print("onnx", results[0])
print("--probabilities--")
print("sklearn", model.predict_proba(X32))
print("onnx", results[1])
print("--validation--")
print("sklearn", model.validate(X32))
print("onnx", results[2])
--labels--
sklearn [1 2 0 1 1]
onnx [1 2 0 1 1]
--probabilities--
sklearn [[4.65660677e-02 6.23801501e-01 3.29632432e-01]
[5.38474410e-04 3.31419819e-01 6.68041707e-01]
[8.84444659e-01 1.15537411e-01 1.79300816e-05]
[5.06447932e-02 7.48704368e-01 2.00650839e-01]
[2.97517300e-01 6.25675007e-01 7.68076934e-02]]
onnx [[4.6566073e-02 6.2380159e-01 3.2963237e-01]
[5.3844741e-04 3.3141989e-01 6.6804165e-01]
[8.8444465e-01 1.1553740e-01 1.7948400e-05]
[5.0644800e-02 7.4870443e-01 2.0065075e-01]
[2.9751724e-01 6.2567514e-01 7.6807626e-02]]
--validation--
sklearn [0 0 1 0 0]
onnx [0 0 1 0 0]
看起來不錯。
顯示 ONNX 圖表¶
pydot_graph = GetPydotGraph(
model_onnx.graph,
name=model_onnx.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("validator_classifier.dot")
os.system("dot -O -Gdpi=300 -Tpng validator_classifier.dot")
image = plt.imread("validator_classifier.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
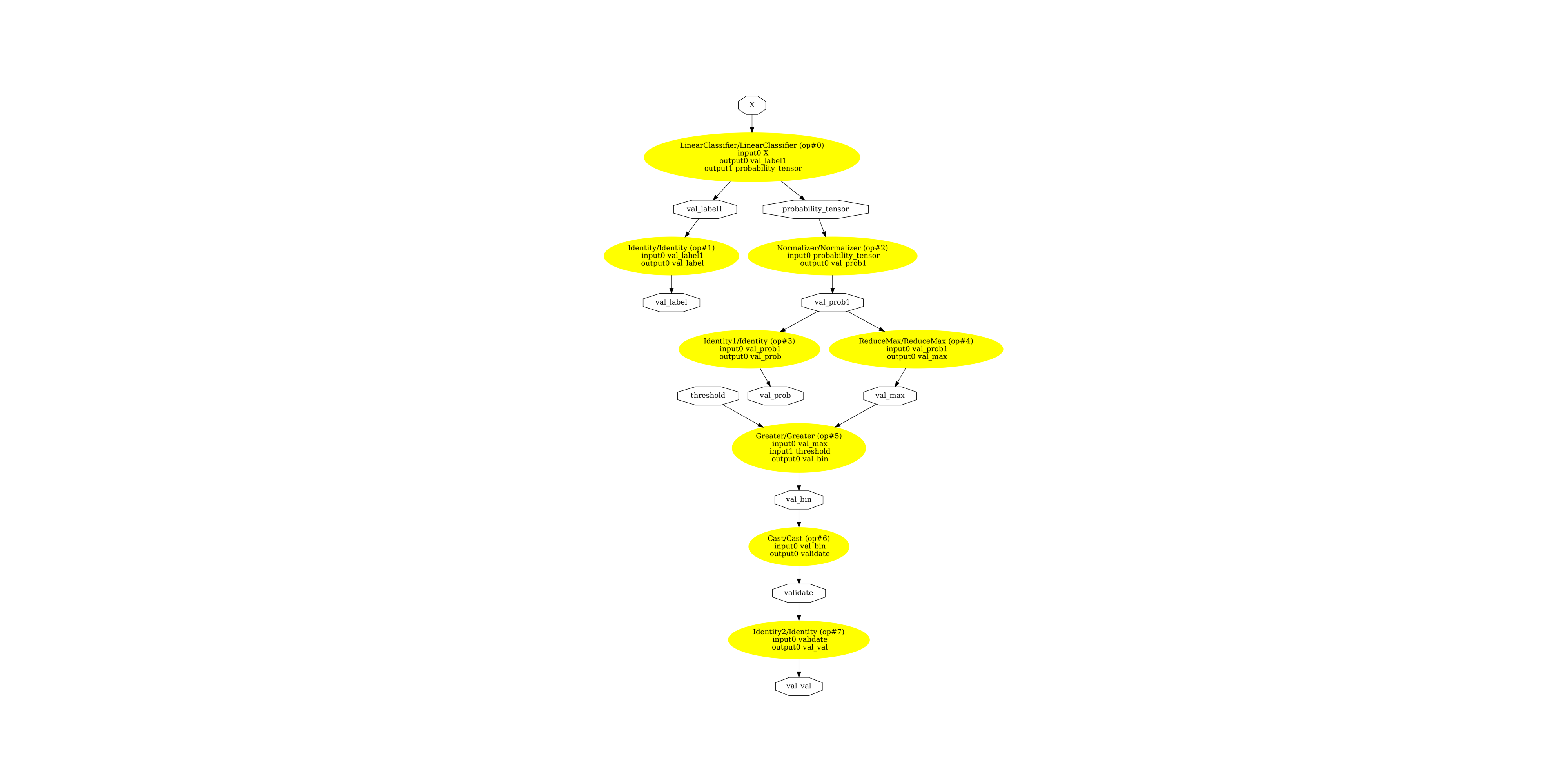
(-0.5, 3293.5, 4934.5, -0.5)
此範例使用的版本
print("numpy:", np.__version__)
print("scikit-learn:", sklearn.__version__)
print("onnx: ", onnx.__version__)
print("onnxruntime: ", rt.__version__)
print("skl2onnx: ", skl2onnx.__version__)
numpy: 1.23.5
scikit-learn: 1.4.dev0
onnx: 1.15.0
onnxruntime: 1.16.0+cu118
skl2onnx: 1.16.0
腳本的總執行時間: (0 分鐘 3.039 秒)