轉換管線¶
skl2onnx 將任何機器學習管線轉換為 ONNX 管線。每個轉換器或預測器都會轉換為 ONNX 圖形中的一個或多個節點。然後,任何 ONNX 後端都可以使用此圖形,針對相同的輸入計算等效的輸出。
轉換複雜的管線¶
scikit-learn 引入了 ColumnTransformer,可用於建構複雜的管線,例如以下管線
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.decomposition import TruncatedSVD
from sklearn.compose import ColumnTransformer
numeric_features = [0, 1, 2] # ["vA", "vB", "vC"]
categorical_features = [3, 4] # ["vcat", "vcat2"]
classifier = LogisticRegression(C=0.01, class_weight=dict(zip([False, True], [0.2, 0.8])),
n_jobs=1, max_iter=10, solver='lbfgs', tol=1e-3)
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())
])
categorical_transformer = Pipeline(steps=[
('onehot', OneHotEncoder(sparse_output=True, handle_unknown='ignore')),
('tsvd', TruncatedSVD(n_components=1, algorithm='arpack', tol=1e-4))
])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)
])
model = Pipeline(steps=[
('precprocessor', preprocessor),
('classifier', classifier)
])
我們可以將其表示為
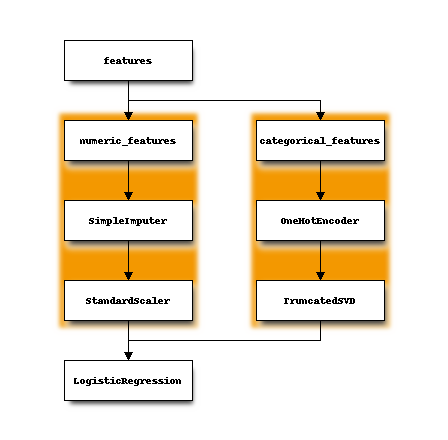
一旦擬合,模型就會轉換為 ONNX
from skl2onnx import convert_sklearn
from skl2onnx.common.data_types import FloatTensorType, StringTensorType
initial_type = [('numfeat', FloatTensorType([None, 3])),
('strfeat', StringTensorType([None, 2]))]
model_onnx = convert_sklearn(model, initial_types=initial_type)
注意
錯誤 AttributeError: 'ColumnTransformer' object has no attribute 'transformers_' 表示模型未經訓練。轉換器嘗試存取方法 fit 所建立的屬性。
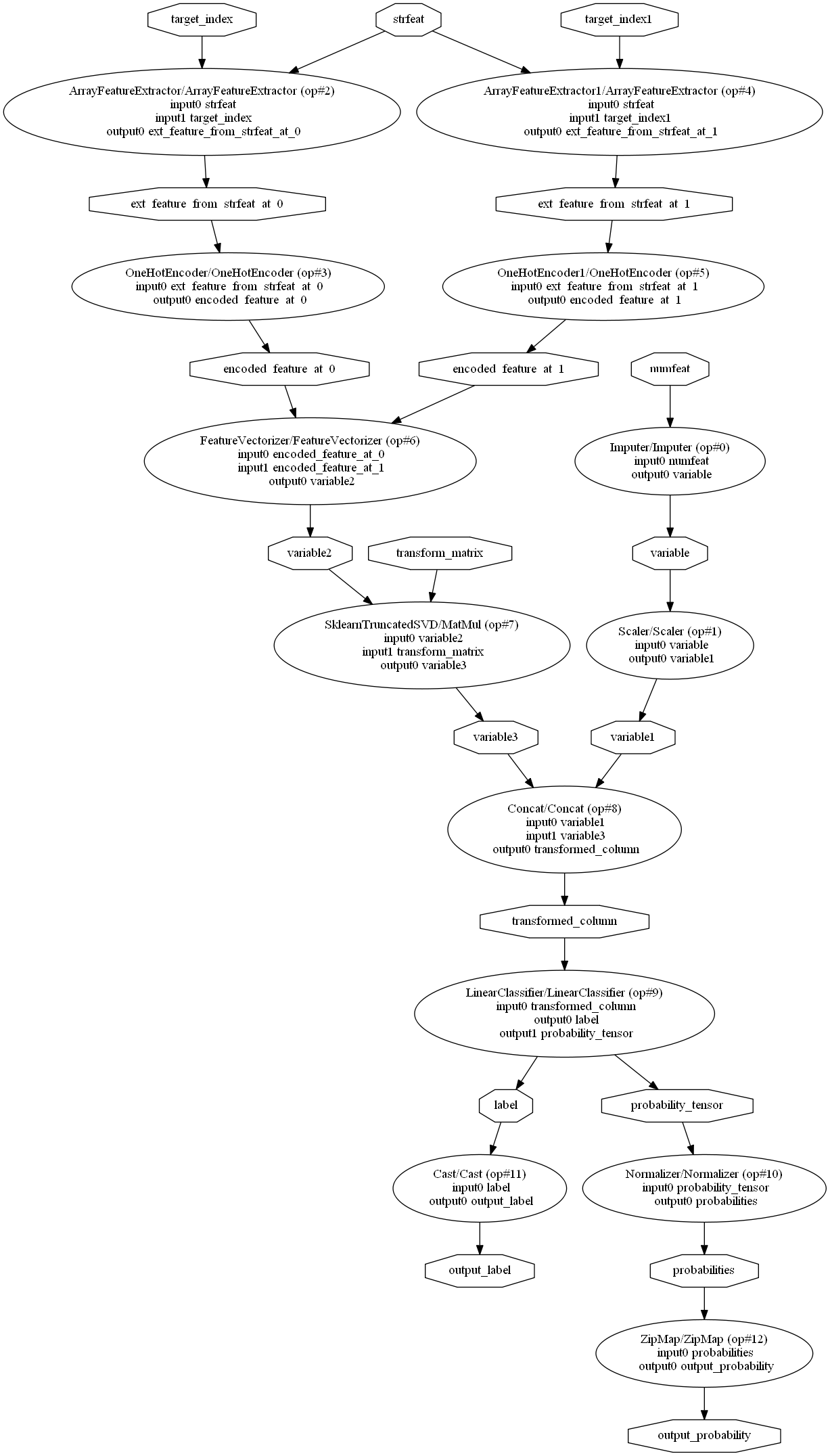
它可以表示為 DOT 圖形
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
pydot_graph = GetPydotGraph(model_onnx.graph, name=model_onnx.graph.name, rankdir="TP",
node_producer=GetOpNodeProducer("docstring"))
pydot_graph.write_dot("graph.dot")
import os
os.system('dot -O -Tpng graph.dot'
剖析器、形狀計算器、轉換器¶
在 scikit-pipeline 的轉換中涉及三種函式。它們會依下列順序呼叫
parser(scope, model, inputs, custom_parser):剖析器會建構模型的預期輸出,由於產生的圖形必須包含唯一名稱,scope 包含所有已給定的名稱,model 是要轉換的模型,inputs 是模型在 ONNX 圖形中接收的 inputs。它是
Variable的清單。custom_parsers 包含一個對應{模型類型: 剖析器},它會延伸預設的剖析器清單。剖析器會定義標準機器學習問題的預設輸出。形狀計算器會根據模型變更每個輸出的形狀和類型,並在定義所有輸出後 (拓撲) 呼叫。此步驟會定義每個節點的輸出數量及其類型,並將其設定為預設形狀[None, None],輸出節點有一列,且尚未有已知的欄。shape_calculator(model): 形狀計算器會變更剖析器所建立的輸出的形狀。一旦此函式傳回結果,圖形結構就會完全定義,而且無法變更。形狀計算器不應變更類型。許多執行階段是以 C++ 實作,而且不支援隱含轉換。類型變更可能會因兩個不同轉換器產生的兩個連續節點之間的類型不符而導致執行階段失敗。
converter(scope, operator, container): 轉換器會將轉換器或預測器轉換為 ONNX 節點。每個節點可以是 ONNX 運算子或 ML 運算子或自訂 ONNX 運算子。
由於 sklearn-onnx 可能會轉換包含來自其他函式庫之模型的管線,因此該函式庫必須處理來自其他套件的剖析器、形狀計算器或轉換器。這可以透過兩種方式完成。第一種方法是呼叫函式 convert_sklearn,將模型類型對應至特定的剖析器、特定的形狀計算器或特定的轉換器。可以透過使用兩個函式 update_registered_converter、update_registered_parser 之一註冊新的剖析器或形狀計算器或轉換器,來避免這些規格。以下是一個範例。
管線中的新轉換器¶
許多函式庫實作了 scikit-learn API,而且它們的模型可以包含在 scikit-learn 管線中。但是,如果 sklearn-onnx 不知道對應的轉換器,則無法轉換包含 XGBoost 或 LightGbm 等模型的管線:它需要註冊。這就是函式 skl2onnx.update_registered_converter() 的目的。下列範例示範如何註冊新的轉換器或更新現有的轉換器。已註冊四個元素
模型類別
別名,通常是類別名稱加上函式庫名稱的前置詞
形狀計算器,它會計算預期輸出的類型和形狀
模型轉換器
下列程式碼會顯示隨機森林的這四個元素為何
from skl2onnx.common.shape_calculator import calculate_linear_classifier_output_shapes
from skl2onnx.operator_converters.RandomForest import convert_sklearn_random_forest_classifier
from skl2onnx import update_registered_converter
update_registered_converter(SGDClassifier, 'SklearnLinearClassifier',
calculate_linear_classifier_output_shapes,
convert_sklearn_random_forest_classifier)
請參閱範例 轉換具有 LightGBM 分類器的管線,以查看具有 LightGbm 模型的完整範例。
鐵達尼號範例¶
第一個範例是來自 scikit-learn 文件中簡化的管線:具有混合類型的資料行轉換器。完整的範例可在可執行的範例中取得:轉換具有 ColumnTransformer 的管線,其中也顯示了使用者在嘗試轉換管線時可能會遇到的一些錯誤。
參數化轉換¶
大多數轉換器都不需要特定選項來轉換 scikit-learn 模型。它總是產生相同的結果。但是,在某些情況下,轉換無法產生傳回完全相同結果的模型。使用者可能想要透過提供轉換器其他資訊來最佳化轉換,即使要轉換的模型包含在管線中也一樣。這就是實作選項機制的理由:具有選項的轉換器。
調查差異¶
不正確的轉換器可能會在轉換器管線中引入差異,但要隔離差異的來源並非總是容易的。然後可以使用函式 collect_intermediate_steps 來獨立調查每個元件。下列程式碼片段取自單元測試 test_investigate.py,並獨立轉換管線及其每個元件。
import numpy
from numpy.testing import assert_almost_equal
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import onnxruntime
from skl2onnx.helpers import collect_intermediate_steps, compare_objects
from skl2onnx.common.data_types import FloatTensorType
# Let's fit a model.
data = numpy.array([[0, 0], [0, 0], [2, 1], [2, 1]],
dtype=numpy.float32)
model = Pipeline([("scaler1", StandardScaler()),
("scaler2", StandardScaler())])
model.fit(data)
# Convert and collect every operator in a pipeline
# and modifies the current pipeline to keep
# intermediate inputs and outputs when method
# predict or transform is called.
operators = collect_intermediate_steps(model, "pipeline",
[("input",
FloatTensorType([None, 2]))])
# Method and transform is called.
model.transform(data)
# Loop on every operator.
for op in operators:
# The ONNX for this operator.
onnx_step = op['onnx_step']
# Use onnxruntime to compute ONNX outputs
sess = onnxruntime.InferenceSession(onnx_step.SerializeToString(),
providers=["CPUExecutionProvider"])
# Let's use the initial data as the ONNX model
# contains all nodes from the first inputs to this node.
onnx_outputs = sess.run(None, {'input': data})
onnx_output = onnx_outputs[0]
skl_outputs = op['model']._debug.outputs['transform']
# Compares the outputs between scikit-learn and onnxruntime.
assert_almost_equal(onnx_output, skl_outputs)
# A function which is able to deal with different types.
compare_objects(onnx_output, skl_outputs)
調查遺失的轉換器¶
在轉換管線之前,可能會遺失許多轉換器。找到第一個遺失的轉換器時,會引發例外 MissingShapeCalculator。可以修改先前的程式碼片段以找出所有遺失的轉換器。
import numpy
from numpy.testing import assert_almost_equal
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
import onnxruntime
from skl2onnx.common.data_types import guess_data_type
from skl2onnx.common.exceptions import MissingShapeCalculator
from skl2onnx.helpers import collect_intermediate_steps, compare_objects, enumerate_pipeline_models
from skl2onnx.helpers.investigate import _alter_model_for_debugging
from skl2onnx import convert_sklearn
class MyScaler(StandardScaler):
pass
# Let's fit a model.
data = numpy.array([[0, 0], [0, 0], [2, 1], [2, 1]],
dtype=numpy.float32)
model = Pipeline([("scaler1", StandardScaler()),
("scaler2", StandardScaler()),
("scaler3", MyScaler()),
])
model.fit(data)
# This function alters the pipeline, every time
# methods transform or predict are used, inputs and outputs
# are stored in every operator.
_alter_model_for_debugging(model, recursive=True)
# Let's use the pipeline and keep intermediate
# inputs and outputs.
model.transform(data)
# Let's get the list of all operators to convert
# and independently process them.
all_models = list(enumerate_pipeline_models(model))
# Loop on every operator.
for ind, op, last in all_models:
if ind == (0,):
# whole pipeline
continue
# The dump input data for this operator.
data_in = op._debug.inputs['transform']
# Let's infer some initial shape.
t = guess_data_type(data_in)
# Let's convert.
try:
onnx_step = convert_sklearn(op, initial_types=t)
except MissingShapeCalculator as e:
if "MyScaler" in str(e):
print(e)
continue
raise
# If it does not fail, let's compare the ONNX outputs with
# the original operator.
sess = onnxruntime.InferenceSession(onnx_step.SerializeToString(),
providers=["CPUExecutionProvider"])
onnx_outputs = sess.run(None, {'input': data_in})
onnx_output = onnx_outputs[0]
skl_outputs = op._debug.outputs['transform']
assert_almost_equal(onnx_output, skl_outputs)
compare_objects(onnx_output, skl_outputs)