注意
前往結尾以下載完整的範例程式碼
ONNX 轉換效能基準測試¶
範例 訓練和部署 scikit-learn 管線 轉換一個簡單模型。此範例使用類似範例,但使用隨機資料,並比較每個選項計算預測所需的時間。
訓練管線¶
import numpy
from pandas import DataFrame
from tqdm import tqdm
from onnx.reference import ReferenceEvaluator
from sklearn import config_context
from sklearn.datasets import make_regression
from sklearn.ensemble import (
GradientBoostingRegressor,
RandomForestRegressor,
VotingRegressor,
)
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from onnxruntime import InferenceSession
from skl2onnx import to_onnx
from skl2onnx.tutorial import measure_time
N = 11000
X, y = make_regression(N, n_features=10)
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.01)
print("Train shape", X_train.shape)
print("Test shape", X_test.shape)
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
ereg = VotingRegressor([("gb", reg1), ("rf", reg2), ("lr", reg3)])
ereg.fit(X_train, y_train)
Train shape (110, 10)
Test shape (10890, 10)
測量處理時間¶
我們使用函式 skl2onnx.tutorial.measure_time()。如果您需要最佳化預測,則有關 assume_finite 的頁面可能會很有用。我們測量每次觀察的處理時間,無論觀察是屬於批次還是單一觀察。
sizes = [(1, 50), (10, 50), (100, 10)]
with config_context(assume_finite=True):
obs = []
for batch_size, repeat in tqdm(sizes):
context = {"ereg": ereg, "X": X_test[:batch_size]}
mt = measure_time(
"ereg.predict(X)", context, div_by_number=True, number=10, repeat=repeat
)
mt["size"] = context["X"].shape[0]
mt["mean_obs"] = mt["average"] / mt["size"]
obs.append(mt)
df_skl = DataFrame(obs)
df_skl
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:07<00:14, 7.06s/it]
67%|██████▋ | 2/3 [00:12<00:06, 6.25s/it]
100%|██████████| 3/3 [00:14<00:00, 4.01s/it]
100%|██████████| 3/3 [00:14<00:00, 4.70s/it]
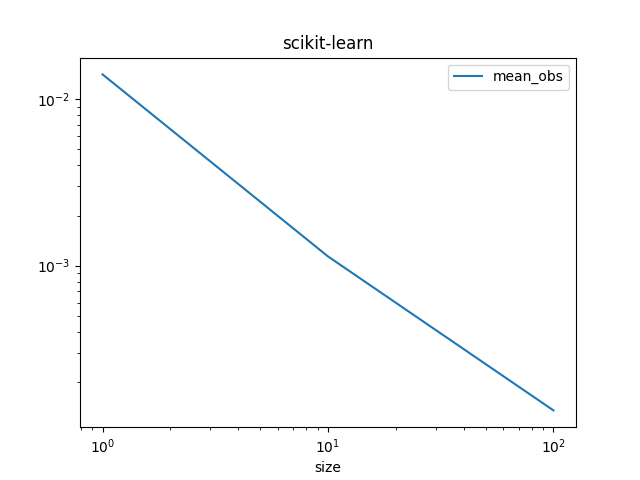
圖表。
df_skl.set_index("size")[["mean_obs"]].plot(title="scikit-learn", logx=True, logy=True)
ONNX Runtime¶
與兩個可用的 ONNX Runtime 執行相同的操作。
onx = to_onnx(ereg, X_train[:1].astype(numpy.float32), target_opset=14)
sess = InferenceSession(onx.SerializeToString(), providers=["CPUExecutionProvider"])
oinf = ReferenceEvaluator(onx)
obs = []
for batch_size, repeat in tqdm(sizes):
# scikit-learn
context = {"ereg": ereg, "X": X_test[:batch_size].astype(numpy.float32)}
mt = measure_time(
"ereg.predict(X)", context, div_by_number=True, number=10, repeat=repeat
)
mt["size"] = context["X"].shape[0]
mt["skl"] = mt["average"] / mt["size"]
# onnxruntime
context = {"sess": sess, "X": X_test[:batch_size].astype(numpy.float32)}
mt2 = measure_time(
"sess.run(None, {'X': X})[0]",
context,
div_by_number=True,
number=10,
repeat=repeat,
)
mt["ort"] = mt2["average"] / mt["size"]
# ReferenceEvaluator
context = {"oinf": oinf, "X": X_test[:batch_size].astype(numpy.float32)}
mt2 = measure_time(
"oinf.run(None, {'X': X})[0]",
context,
div_by_number=True,
number=10,
repeat=repeat,
)
mt["pyrt"] = mt2["average"] / mt["size"]
# end
obs.append(mt)
df = DataFrame(obs)
df
0%| | 0/3 [00:00<?, ?it/s]
33%|███▎ | 1/3 [00:15<00:31, 15.60s/it]
67%|██████▋ | 2/3 [00:40<00:21, 21.10s/it]
100%|██████████| 3/3 [01:03<00:00, 21.84s/it]
100%|██████████| 3/3 [01:03<00:00, 21.09s/it]
圖表。
df.set_index("size")[["skl", "ort", "pyrt"]].plot(
title="Average prediction time per runtime", logx=True, logy=True
)
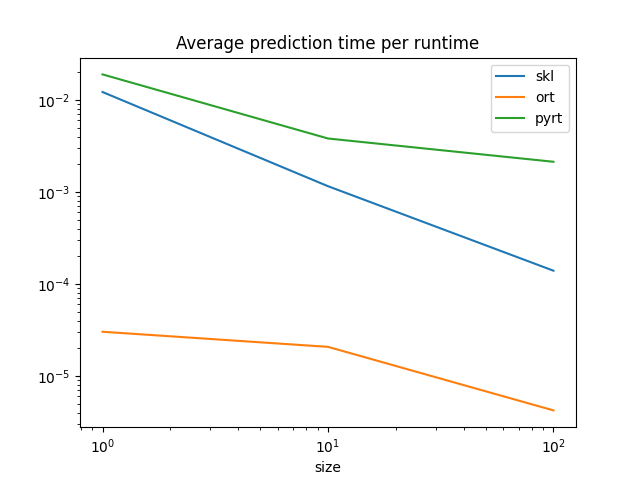
ONNX Runtime 比 scikit-learn 預測單一觀察的速度快得多。scikit-learn 針對訓練和批次預測進行最佳化。這解釋了為什麼 scikit-learn 和 ONNX Runtime 對於大型批次似乎會趨於一致。它們使用類似的實作、平行化和語言 (C++、openmp)。
腳本的總執行時間:(1 分 19.181 秒)