注意
前往結尾 以下載完整的範例程式碼。
逐步檢視中間輸出¶
我們重複使用範例 轉換具有 ColumnTransformer 的管線 並逐步檢視中間輸出。轉換後的模型很可能因為未正確實作的自訂轉換器而產生不同的輸出或失敗。一個選項是檢視 ONNX 圖形的每個節點的輸出。
建立並訓練複雜管線¶
我們重複使用範例 Column Transformer with Mixed Types 中實作的管線。有一個變更,因為 ONNX-ML Imputer 不處理字串類型。這不能是最終 ONNX 管線的一部分,必須移除。尋找以下以 --- 開頭的註解。
import skl2onnx
import onnx
import sklearn
import matplotlib.pyplot as plt
import os
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
from skl2onnx.helpers.onnx_helper import select_model_inputs_outputs
from skl2onnx.helpers.onnx_helper import save_onnx_model
from skl2onnx.helpers.onnx_helper import enumerate_model_node_outputs
from skl2onnx.helpers.onnx_helper import load_onnx_model
import numpy
import onnxruntime as rt
from skl2onnx import convert_sklearn
import pprint
from skl2onnx.common.data_types import (
FloatTensorType,
StringTensorType,
Int64TensorType,
)
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
titanic_url = (
"https://raw.githubusercontent.com/amueller/"
"scipy-2017-sklearn/091d371/notebooks/datasets/titanic3.csv"
)
data = pd.read_csv(titanic_url)
X = data.drop("survived", axis=1)
y = data["survived"]
# SimpleImputer on string is not available
# for string in ONNX-ML specifications.
# So we do it beforehand.
for cat in ["embarked", "sex", "pclass"]:
X[cat].fillna("missing", inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
numeric_features = ["age", "fare"]
numeric_transformer = Pipeline(
steps=[("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler())]
)
categorical_features = ["embarked", "sex", "pclass"]
categorical_transformer = Pipeline(
steps=[
# --- SimpleImputer is not available for strings in ONNX-ML specifications.
# ('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
("onehot", OneHotEncoder(handle_unknown="ignore"))
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features),
]
)
clf = Pipeline(
steps=[
("preprocessor", preprocessor),
("classifier", LogisticRegression(solver="lbfgs")),
]
)
clf.fit(X_train, y_train)
定義 ONNX 圖形的輸入¶
sklearn-onnx 不知道用於訓練模型的特徵,但需要知道哪個特徵具有哪個名稱。我們只需重複使用 DataFrame 資料行定義。
print(X_train.dtypes)
pclass int64
name object
sex object
age float64
sibsp int64
parch int64
ticket object
fare float64
cabin object
embarked object
boat object
body float64
home.dest object
dtype: object
轉換後。
def convert_dataframe_schema(df, drop=None):
inputs = []
for k, v in zip(df.columns, df.dtypes):
if drop is not None and k in drop:
continue
if v == "int64":
t = Int64TensorType([None, 1])
elif v == "float64":
t = FloatTensorType([None, 1])
else:
t = StringTensorType([None, 1])
inputs.append((k, t))
return inputs
inputs = convert_dataframe_schema(X_train)
pprint.pprint(inputs)
[('pclass', Int64TensorType(shape=[None, 1])),
('name', StringTensorType(shape=[None, 1])),
('sex', StringTensorType(shape=[None, 1])),
('age', FloatTensorType(shape=[None, 1])),
('sibsp', Int64TensorType(shape=[None, 1])),
('parch', Int64TensorType(shape=[None, 1])),
('ticket', StringTensorType(shape=[None, 1])),
('fare', FloatTensorType(shape=[None, 1])),
('cabin', StringTensorType(shape=[None, 1])),
('embarked', StringTensorType(shape=[None, 1])),
('boat', StringTensorType(shape=[None, 1])),
('body', FloatTensorType(shape=[None, 1])),
('home.dest', StringTensorType(shape=[None, 1]))]
將單一資料行合併成向量並不是計算預測最有效的方式。這可以在將管線轉換為圖形之前完成。
將管線轉換為 ONNX¶
try:
model_onnx = convert_sklearn(clf, "pipeline_titanic", inputs, target_opset=12)
except Exception as e:
print(e)
scikit-learn 會在可以時進行隱含轉換。sklearn-onnx 不會。OneHotEncoder 的 ONNX 版本必須應用於相同類型的資料行。
X_train["pclass"] = X_train["pclass"].astype(str)
X_test["pclass"] = X_test["pclass"].astype(str)
white_list = numeric_features + categorical_features
to_drop = [c for c in X_train.columns if c not in white_list]
inputs = convert_dataframe_schema(X_train, to_drop)
model_onnx = convert_sklearn(clf, "pipeline_titanic", inputs, target_opset=12)
# And save.
with open("pipeline_titanic.onnx", "wb") as f:
f.write(model_onnx.SerializeToString())
比較預測¶
最後一步,我們需要確保轉換後的模型產生相同的預測、標籤和機率。讓我們從 scikit-learn 開始。
predict [0 0 1 0 0]
predict_proba [[0.60224126 0.39775874]]
使用 onnxruntime 進行預測。我們需要移除已刪除的資料行,並將雙精度向量變更為浮點向量,因為 onnxruntime 不支援雙精度浮點數。onnxruntime 不接受 DataFrame。輸入必須以字典清單的形式給定。最後的細節,每個資料行實際上並不是被描述為向量,而是被描述為單一資料行的矩陣,這解釋了最後一行使用 reshape 的原因。
我們準備好執行 onnxruntime 了。
predict [0 0 1 0 0]
predict_proba [{0: 0.7899309396743774, 1: 0.21006903052330017}]
計算中間輸出¶
不幸的是,實際上沒有辦法要求 onnxruntime 擷取中間節點的輸出。我們需要在將 ONNX 提供給 onnxruntime 之前修改它。讓我們先看看中間輸出的列表。
merged_columns
embarkedout
sexout
pclassout
concat_result
variable
variable2
variable1
transformed_column
label
probabilities
output_label
output_probability
很難判斷哪個是什麼,因為 ONNX 的運算子比原始 scikit-learn 管線還要多。顯示 ONNX 圖形 的圖形有助於找出數值和文字管線的輸出:variable1、variable2。讓我們先研究數值管線。
num_onnx = select_model_inputs_outputs(model_onnx, "variable1")
save_onnx_model(num_onnx, "pipeline_titanic_numerical.onnx")
b'\x08\x07\x12\x08skl2onnx\x1a\x061.17.0"\x07ai.onnx(\x002\x00:\xcd\x03\n:\n\x03age\n\x04fare\x12\x0emerged_columns\x1a\x06Concat"\x06Concat*\x0b\n\x04axis\x18\x01\xa0\x01\x02:\x00\n}\n\x0emerged_columns\x12\x08variable\x1a\x07Imputer"\x07Imputer*#\n\x14imputed_value_floats=\x00\x00\xe2A=\xcdLgA\xa0\x01\x06*\x1e\n\x14replaced_value_float\x15\x00\x00\xc0\x7f\xa0\x01\x01:\nai.onnx.ml\n^\n\x08variable\x12\tvariable1\x1a\x06Scaler"\x06Scaler*\x15\n\x06offset=\xe05\xedA=\'\xcb\nB\xa0\x01\x06*\x14\n\x05scale=\'l\x9f==\xdd,\x96<\xa0\x01\x06:\nai.onnx.ml\x12\x10pipeline_titanic*\x1f\x08\x02\x10\x07:\x0b\xff\xff\xff\xff\xff\xff\xff\xff\xff\x01\tB\x0cshape_tensorZ\x16\n\x06pclass\x12\x0c\n\n\x08\x08\x12\x06\n\x00\n\x02\x08\x01Z\x13\n\x03sex\x12\x0c\n\n\x08\x08\x12\x06\n\x00\n\x02\x08\x01Z\x13\n\x03age\x12\x0c\n\n\x08\x01\x12\x06\n\x00\n\x02\x08\x01Z\x14\n\x04fare\x12\x0c\n\n\x08\x01\x12\x06\n\x00\n\x02\x08\x01Z\x18\n\x08embarked\x12\x0c\n\n\x08\x08\x12\x06\n\x00\n\x02\x08\x01b\x0b\n\tvariable1B\x0e\n\nai.onnx.ml\x10\x01B\x04\n\x00\x10\x0b'
讓我們計算數值特徵。
numerical features [[-0.7512866 -0.50364053]]
我們對文字特徵執行相同的操作。
print(model_onnx)
text_onnx = select_model_inputs_outputs(model_onnx, "variable2")
save_onnx_model(text_onnx, "pipeline_titanic_textual.onnx")
sess = rt.InferenceSession(
"pipeline_titanic_textual.onnx", providers=["CPUExecutionProvider"]
)
numT = sess.run(None, inputs)
print("textual features", numT[0][:1])
ir_version: 7
opset_import {
domain: "ai.onnx.ml"
version: 1
}
opset_import {
domain: ""
version: 11
}
producer_name: "skl2onnx"
producer_version: "1.17.0"
domain: "ai.onnx"
model_version: 0
doc_string: ""
graph {
node {
input: "age"
input: "fare"
output: "merged_columns"
name: "Concat"
op_type: "Concat"
domain: ""
attribute {
name: "axis"
type: INT
i: 1
}
}
node {
input: "embarked"
output: "embarkedout"
name: "OneHotEncoder"
op_type: "OneHotEncoder"
domain: "ai.onnx.ml"
attribute {
name: "cats_strings"
type: STRINGS
strings: "C"
strings: "Q"
strings: "S"
strings: "missing"
}
attribute {
name: "zeros"
type: INT
i: 1
}
}
node {
input: "sex"
output: "sexout"
name: "OneHotEncoder1"
op_type: "OneHotEncoder"
domain: "ai.onnx.ml"
attribute {
name: "cats_strings"
type: STRINGS
strings: "female"
strings: "male"
}
attribute {
name: "zeros"
type: INT
i: 1
}
}
node {
input: "pclass"
output: "pclassout"
name: "OneHotEncoder2"
op_type: "OneHotEncoder"
domain: "ai.onnx.ml"
attribute {
name: "cats_strings"
type: STRINGS
strings: "1"
strings: "2"
strings: "3"
}
attribute {
name: "zeros"
type: INT
i: 1
}
}
node {
input: "embarkedout"
input: "sexout"
input: "pclassout"
output: "concat_result"
name: "Concat1"
op_type: "Concat"
domain: ""
attribute {
name: "axis"
type: INT
i: -1
}
}
node {
input: "merged_columns"
output: "variable"
name: "Imputer"
op_type: "Imputer"
domain: "ai.onnx.ml"
attribute {
name: "imputed_value_floats"
type: FLOATS
floats: 28.25
floats: 14.4562502
}
attribute {
name: "replaced_value_float"
type: FLOAT
f: nan
}
}
node {
input: "concat_result"
input: "shape_tensor"
output: "variable2"
name: "Reshape"
op_type: "Reshape"
domain: ""
}
node {
input: "variable"
output: "variable1"
name: "Scaler"
op_type: "Scaler"
domain: "ai.onnx.ml"
attribute {
name: "offset"
type: FLOATS
floats: 29.6513062
floats: 34.698391
}
attribute {
name: "scale"
type: FLOATS
floats: 0.077843
floats: 0.0183319394
}
}
node {
input: "variable1"
input: "variable2"
output: "transformed_column"
name: "Concat2"
op_type: "Concat"
domain: ""
attribute {
name: "axis"
type: INT
i: 1
}
}
node {
input: "transformed_column"
output: "label"
output: "probabilities"
name: "LinearClassifier"
op_type: "LinearClassifier"
domain: "ai.onnx.ml"
attribute {
name: "classlabels_ints"
type: INTS
ints: 0
ints: 1
}
attribute {
name: "coefficients"
type: FLOATS
floats: 0.411349356
floats: -0.0257858913
floats: -0.341414243
floats: 0.0805286616
floats: 0.334271878
floats: -0.121588431
floats: -1.24841082
floats: 1.20020878
floats: -0.920275748
floats: -0.037623141
floats: 0.909696758
floats: -0.411349356
floats: 0.0257858913
floats: 0.341414243
floats: -0.0805286616
floats: -0.334271878
floats: 0.121588431
floats: 1.24841082
floats: -1.20020878
floats: 0.920275748
floats: 0.037623141
floats: -0.909696758
}
attribute {
name: "intercepts"
type: FLOATS
floats: -0.147927582
floats: 0.147927582
}
attribute {
name: "multi_class"
type: INT
i: 0
}
attribute {
name: "post_transform"
type: STRING
s: "LOGISTIC"
}
}
node {
input: "label"
output: "output_label"
name: "Cast"
op_type: "Cast"
domain: ""
attribute {
name: "to"
type: INT
i: 7
}
}
node {
input: "probabilities"
output: "output_probability"
name: "ZipMap"
op_type: "ZipMap"
domain: "ai.onnx.ml"
attribute {
name: "classlabels_int64s"
type: INTS
ints: 0
ints: 1
}
}
name: "pipeline_titanic"
initializer {
dims: 2
data_type: 7
int64_data: -1
int64_data: 9
name: "shape_tensor"
}
input {
name: "pclass"
type {
tensor_type {
elem_type: 8
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "sex"
type {
tensor_type {
elem_type: 8
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "age"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "fare"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
input {
name: "embarked"
type {
tensor_type {
elem_type: 8
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
output {
name: "output_label"
type {
tensor_type {
elem_type: 7
shape {
dim {
}
}
}
}
}
output {
name: "output_probability"
type {
sequence_type {
elem_type {
map_type {
key_type: 7
value_type {
tensor_type {
elem_type: 1
}
}
}
}
}
}
}
}
textual features [[1. 0. 0. 0. 0. 1. 0. 0. 1.]]
顯示子 ONNX 圖形¶
最後,讓我們看看兩個子圖形。首先是數值管線。
pydot_graph = GetPydotGraph(
num_onnx.graph,
name=num_onnx.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("pipeline_titanic_num.dot")
os.system("dot -O -Gdpi=300 -Tpng pipeline_titanic_num.dot")
image = plt.imread("pipeline_titanic_num.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
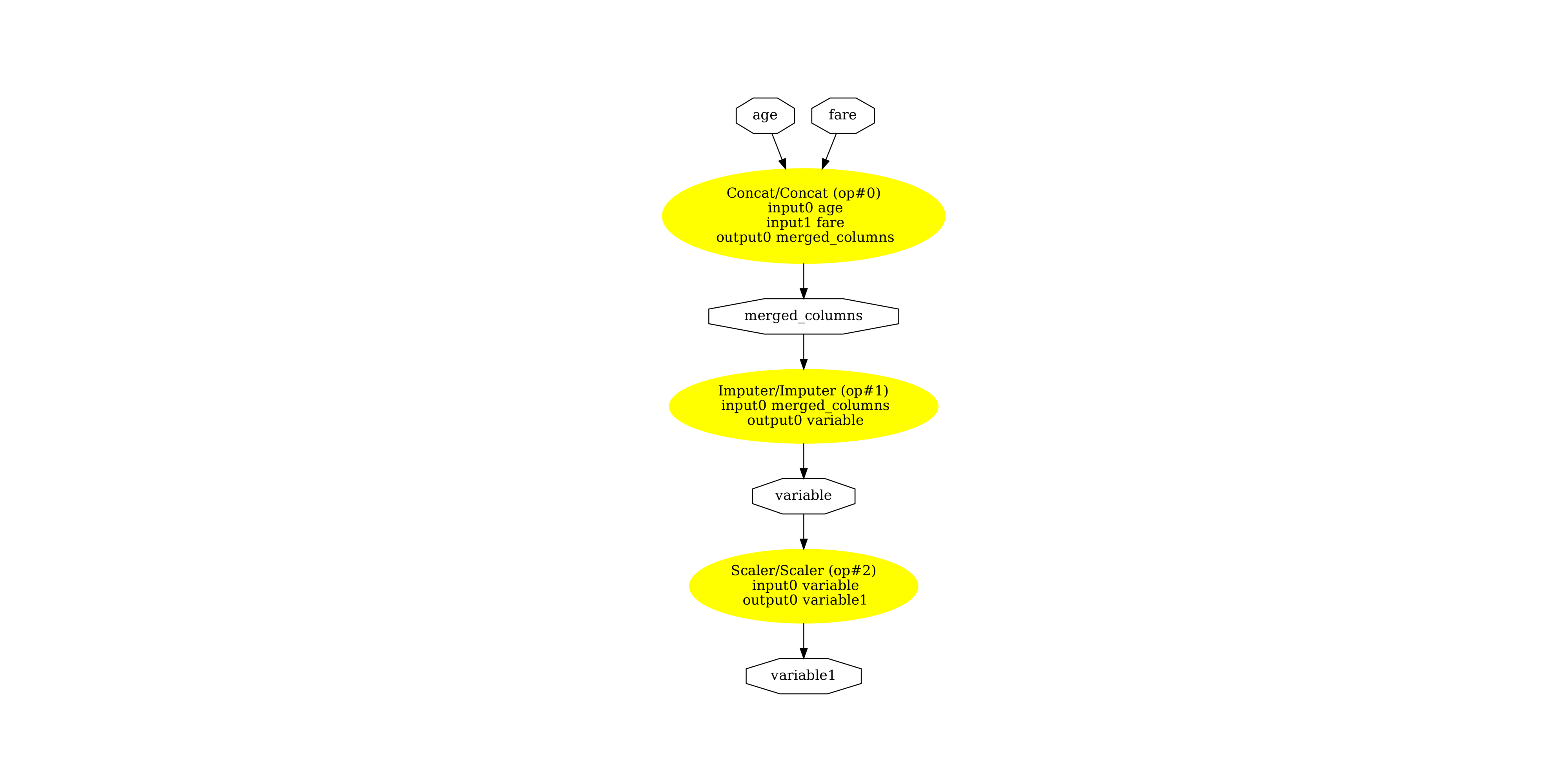
(-0.5, 1229.5, 2558.5, -0.5)
然後是文字管線。
pydot_graph = GetPydotGraph(
text_onnx.graph,
name=text_onnx.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer(
"docstring", color="yellow", fillcolor="yellow", style="filled"
),
)
pydot_graph.write_dot("pipeline_titanic_text.dot")
os.system("dot -O -Gdpi=300 -Tpng pipeline_titanic_text.dot")
image = plt.imread("pipeline_titanic_text.dot.png")
fig, ax = plt.subplots(figsize=(40, 20))
ax.imshow(image)
ax.axis("off")
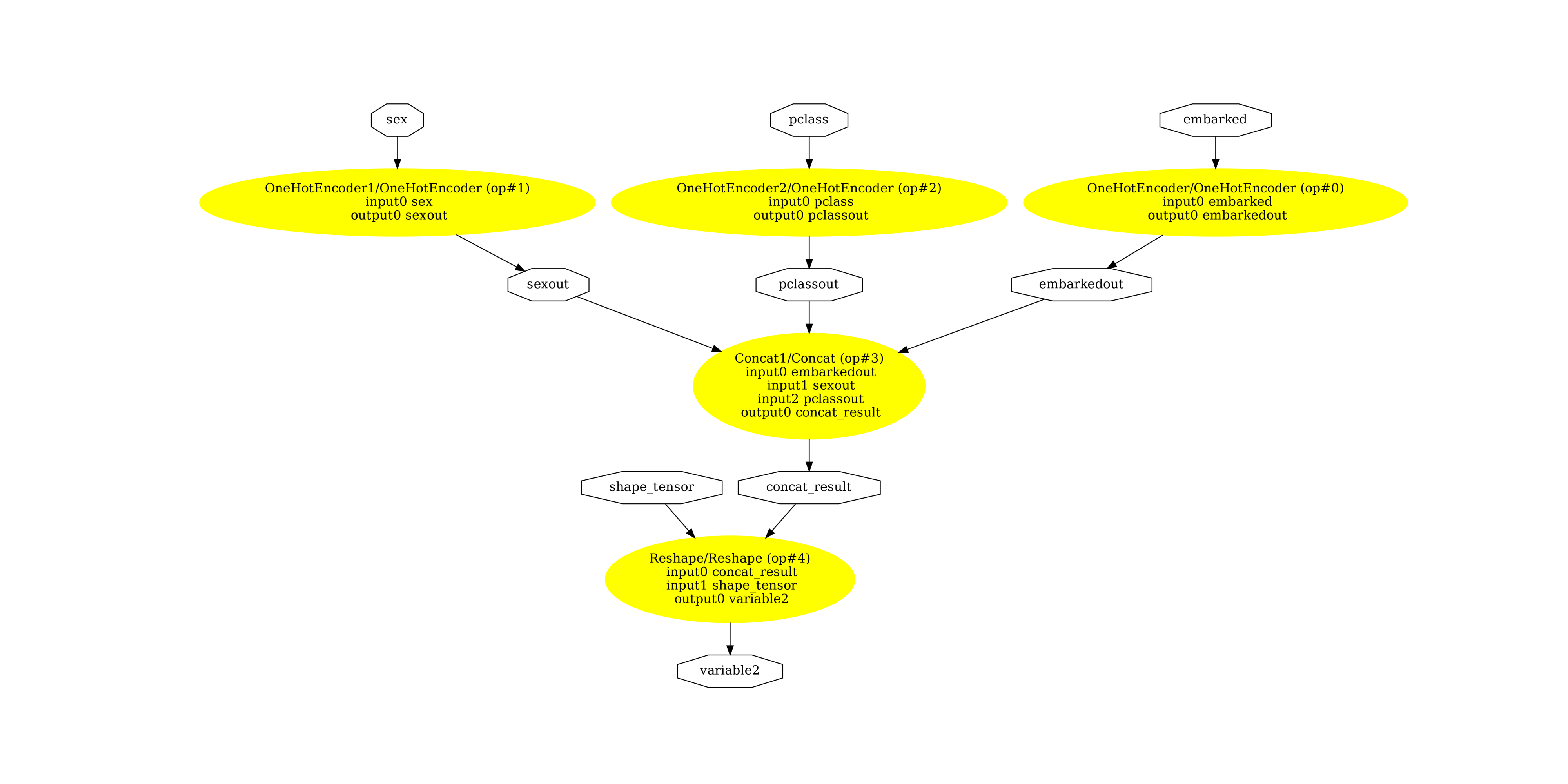
(-0.5, 5630.5, 2735.5, -0.5)
此範例使用的版本
print("numpy:", numpy.__version__)
print("scikit-learn:", sklearn.__version__)
print("onnx: ", onnx.__version__)
print("onnxruntime: ", rt.__version__)
print("skl2onnx: ", skl2onnx.__version__)
numpy: 1.26.4
scikit-learn: 1.6.dev0
onnx: 1.17.0
onnxruntime: 1.18.0+cu118
skl2onnx: 1.17.0
腳本總執行時間: (0 分鐘 4.738 秒)