注意
前往結尾以下載完整範例程式碼
NMF 分解的自訂運算子¶
NMF 將輸入矩陣分解成兩個秩為 k 的矩陣 W, H,因此 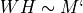 。
。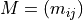 可以是二元矩陣,其中 i 是使用者,j 是他購買的產品。預測函數取決於使用者是否需要為現有使用者或新使用者提供建議。此範例說明第一種情況。
可以是二元矩陣,其中 i 是使用者,j 是他購買的產品。預測函數取決於使用者是否需要為現有使用者或新使用者提供建議。此範例說明第一種情況。
第二種情況較為複雜,因為理論上需要使用梯度下降來估計新的矩陣 W。
建構簡單模型¶
import os
import skl2onnx
import onnxruntime
import sklearn
from sklearn.decomposition import NMF
import numpy as np
import matplotlib.pyplot as plt
from onnx.tools.net_drawer import GetPydotGraph, GetOpNodeProducer
import onnx
from skl2onnx.algebra.onnx_ops import OnnxArrayFeatureExtractor, OnnxMul, OnnxReduceSum
from skl2onnx.common.data_types import FloatTensorType
from onnxruntime import InferenceSession
mat = np.array(
[[1, 0, 0, 0], [1, 0, 0, 0], [1, 0, 0, 0], [1, 0, 0, 0], [1, 0, 0, 0]],
dtype=np.float64,
)
mat[: mat.shape[1], :] += np.identity(mat.shape[1])
mod = NMF(n_components=2)
W = mod.fit_transform(mat)
H = mod.components_
pred = mod.inverse_transform(W)
print("original predictions")
exp = []
for i in range(mat.shape[0]):
for j in range(mat.shape[1]):
exp.append((i, j, pred[i, j]))
print(exp)
original predictions
[(0, 0, 1.8940507356352687), (0, 1, 0.10912372262184848), (0, 2, 0.3072453141962623), (0, 3, 0.3072453141962623), (1, 0, 1.014673742790866), (1, 1, 0.9848866016414943), (1, 2, 0.0), (1, 3, 0.0), (2, 0, 1.1066115912409111), (2, 1, 0.0), (2, 2, 0.19083752823558645), (2, 3, 0.19083752823558645), (3, 0, 1.1066115912409111), (3, 1, 0.0), (3, 2, 0.19083752823558645), (3, 3, 0.19083752823558645), (4, 0, 0.9470253678176344), (4, 1, 0.05456186131092424), (4, 2, 0.15362265709813114), (4, 3, 0.15362265709813114)]
讓我們以更接近我們需要轉換為 ONNX 的函數的方式重寫預測。
[(0, 0, 1.8940507356352687), (0, 1, 0.10912372262184848), (0, 2, 0.3072453141962623), (0, 3, 0.3072453141962623), (1, 0, 1.014673742790866), (1, 1, 0.9848866016414943), (1, 2, 0.0), (1, 3, 0.0), (2, 0, 1.1066115912409111), (2, 1, 0.0), (2, 2, 0.19083752823558645), (2, 3, 0.19083752823558645), (3, 0, 1.1066115912409111), (3, 1, 0.0), (3, 2, 0.19083752823558645), (3, 3, 0.19083752823558645), (4, 0, 0.9470253678176344), (4, 1, 0.05456186131092424), (4, 2, 0.15362265709813114), (4, 3, 0.15362265709813114)]
轉換為 ONNX¶
由於我們計劃轉換的函數不是轉換器或預測器,因此沒有為 NMF 實作轉換器。以下轉換器不需要註冊,它只會建立與上面實作的函數 predict 等效的 ONNX 圖。
def nmf_to_onnx(W, H, op_version=12):
"""
The function converts a NMF described by matrices
*W*, *H* (*WH* approximate training data *M*).
into a function which takes two indices *(i, j)*
and returns the predictions for it. It assumes
these indices applies on the training data.
"""
col = OnnxArrayFeatureExtractor(H, "col")
row = OnnxArrayFeatureExtractor(W.T, "row")
dot = OnnxMul(col, row, op_version=op_version)
res = OnnxReduceSum(dot, output_names="rec", op_version=op_version)
indices_type = np.array([0], dtype=np.int64)
onx = res.to_onnx(
inputs={"col": indices_type, "row": indices_type},
outputs=[("rec", FloatTensorType((None, 1)))],
target_opset=op_version,
)
return onx
model_onnx = nmf_to_onnx(W.astype(np.float32), H.astype(np.float32))
print(model_onnx)
ir_version: 7
opset_import {
domain: ""
version: 12
}
opset_import {
domain: "ai.onnx.ml"
version: 1
}
producer_name: "skl2onnx"
producer_version: "1.16.0"
domain: "ai.onnx"
model_version: 0
graph {
node {
input: "Ar_ArrayFeatureExtractorcst"
input: "col"
output: "Ar_Z0"
name: "Ar_ArrayFeatureExtractor"
op_type: "ArrayFeatureExtractor"
domain: "ai.onnx.ml"
}
node {
input: "Ar_ArrayFeatureExtractorcst1"
input: "row"
output: "Ar_Z02"
name: "Ar_ArrayFeatureExtractor1"
op_type: "ArrayFeatureExtractor"
domain: "ai.onnx.ml"
}
node {
input: "Ar_Z0"
input: "Ar_Z02"
output: "Mu_C0"
name: "Mu_Mul"
op_type: "Mul"
domain: ""
}
node {
input: "Mu_C0"
output: "rec"
name: "Re_ReduceSum"
op_type: "ReduceSum"
domain: ""
}
name: "OnnxReduceSum"
initializer {
dims: 2
dims: 4
data_type: 1
float_data: 1.98630548
float_data: 0
float_data: 0.342542619
float_data: 0.342542619
float_data: 0.900879145
float_data: 0.874432623
float_data: 0
float_data: 0
name: "Ar_ArrayFeatureExtractorcst"
}
initializer {
dims: 2
dims: 5
data_type: 1
float_data: 0.896955
float_data: 0
float_data: 0.557120502
float_data: 0.557120502
float_data: 0.448477507
float_data: 0.124793746
float_data: 1.126315
float_data: 0
float_data: 0
float_data: 0.0623968728
name: "Ar_ArrayFeatureExtractorcst1"
}
input {
name: "col"
type {
tensor_type {
elem_type: 7
shape {
dim {
}
}
}
}
}
input {
name: "row"
type {
tensor_type {
elem_type: 7
shape {
dim {
}
}
}
}
}
output {
name: "rec"
type {
tensor_type {
elem_type: 1
shape {
dim {
}
dim {
dim_value: 1
}
}
}
}
}
}
讓我們用它來計算預測。
sess = InferenceSession(
model_onnx.SerializeToString(), providers=["CPUExecutionProvider"]
)
def predict_onnx(sess, row_indices, col_indices):
res = sess.run(None, {"col": col_indices, "row": row_indices})
return res
onnx_preds = []
for i in range(mat.shape[0]):
for j in range(mat.shape[1]):
row_indices = np.array([i], dtype=np.int64)
col_indices = np.array([j], dtype=np.int64)
pred = predict_onnx(sess, row_indices, col_indices)[0]
onnx_preds.append((i, j, pred[0, 0]))
print(onnx_preds)
[(0, 0, 1.8940508), (0, 1, 0.10912372), (0, 2, 0.3072453), (0, 3, 0.3072453), (1, 0, 1.0146737), (1, 1, 0.9848866), (1, 2, 0.0), (1, 3, 0.0), (2, 0, 1.1066115), (2, 1, 0.0), (2, 2, 0.19083752), (2, 3, 0.19083752), (3, 0, 1.1066115), (3, 1, 0.0), (3, 2, 0.19083752), (3, 3, 0.19083752), (4, 0, 0.9470254), (4, 1, 0.05456186), (4, 2, 0.15362266), (4, 3, 0.15362266)]
ONNX 圖如下所示。
pydot_graph = GetPydotGraph(
model_onnx.graph,
name=model_onnx.graph.name,
rankdir="TB",
node_producer=GetOpNodeProducer("docstring"),
)
pydot_graph.write_dot("graph_nmf.dot")
os.system("dot -O -Tpng graph_nmf.dot")
image = plt.imread("graph_nmf.dot.png")
plt.imshow(image)
plt.axis("off")
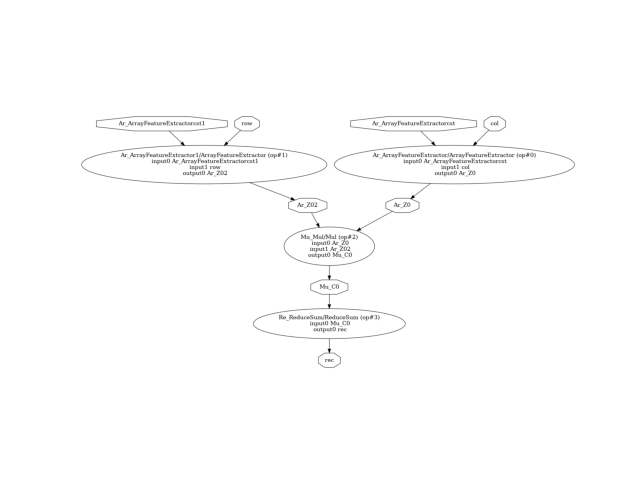
(-0.5, 1654.5, 846.5, -0.5)
此範例使用的版本
print("numpy:", np.__version__)
print("scikit-learn:", sklearn.__version__)
print("onnx: ", onnx.__version__)
print("onnxruntime: ", onnxruntime.__version__)
print("skl2onnx: ", skl2onnx.__version__)
numpy: 1.23.5
scikit-learn: 1.4.dev0
onnx: 1.15.0
onnxruntime: 1.16.0+cu118
skl2onnx: 1.16.0
腳本的總執行時間:(0 分鐘 0.298 秒)