注意
前往結尾下載完整範例程式碼。
轉換帶有 LightGBM 迴歸器的管線¶
當使用浮點數和 TreeEnsemble 運算子時觀察到的差異(請參閱切換至浮點數時的問題)說明了為何 LGBMRegressor 的轉換器即使在使用浮點數張量時也可能會產生顯著差異。
函式庫 lightgbm 是以雙精度浮點數實作。具有多個樹狀結構的隨機森林迴歸器會透過加總每棵樹的預測來計算其預測。在轉換為 ONNX 之後,此加總會變成 ![\left[\sum\right]_{i=1}^F float(T_i(x))](../_images/math/a2d1c2f56276e05e34f6d2fc904dc71680fc1914.png) ,其中 F 是森林中的樹木數量,
,其中 F 是森林中的樹木數量,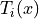 是樹木 i 的輸出,而
是樹木 i 的輸出,而 ![\left[\sum\right]](../_images/math/c4db1c515ae99a7a1062382cd305c1692428c162.png) 則是浮點數加法。差異可以表示為
則是浮點數加法。差異可以表示為 ![D(x) = |\left[\sum\right]_{i=1}^F float(T_i(x)) - \sum_{i=1}^F T_i(x)|](../_images/math/51210b969861f7df2fe22a76b7d03477a0aa7ce6.png) 。這會隨著森林中樹木的數量而增加。
。這會隨著森林中樹木的數量而增加。
為了減少影響,新增了一個選項,將節點 TreeEnsembleRegressor 分割成多個節點,這次改用雙精度浮點數進行加總。如果我們假設節點分割成 a 個節點,則差異會變成 ![D'(x) = |\sum_{k=1}^a \left[\sum\right]_{i=1}^{F/a} float(T_{ak + i}(x)) - \sum_{i=1}^F T_i(x)|](../_images/math/070692ac1405bf91a81a00816ad6fcaf5be87264.png) 。
。
訓練 LGBMRegressor¶
import packaging.version as pv
import warnings
import timeit
import numpy
from pandas import DataFrame
import matplotlib.pyplot as plt
from tqdm import tqdm
from lightgbm import LGBMRegressor
from onnxruntime import InferenceSession
from skl2onnx import to_onnx, update_registered_converter
from skl2onnx.common.shape_calculator import (
calculate_linear_regressor_output_shapes,
) # noqa
from onnxmltools import __version__ as oml_version
from onnxmltools.convert.lightgbm.operator_converters.LightGbm import (
convert_lightgbm,
) # noqa
N = 1000
X = numpy.random.randn(N, 20)
y = numpy.random.randn(N) + numpy.random.randn(N) * 100 * numpy.random.randint(
0, 1, 1000
)
reg = LGBMRegressor(n_estimators=1000)
reg.fit(X, y)
[LightGBM] [Info] Auto-choosing col-wise multi-threading, the overhead of testing was 0.000276 seconds.
You can set `force_col_wise=true` to remove the overhead.
[LightGBM] [Info] Total Bins 5100
[LightGBM] [Info] Number of data points in the train set: 1000, number of used features: 20
[LightGBM] [Info] Start training from score 0.001127
註冊 LGBMClassifier 的轉換器¶
轉換器實作於onnxmltools:onnxmltools…LightGbm.py。以及形狀計算器:onnxmltools…Regressor.py。
def skl2onnx_convert_lightgbm(scope, operator, container):
options = scope.get_options(operator.raw_operator)
if "split" in options:
if pv.Version(oml_version) < pv.Version("1.9.2"):
warnings.warn(
"Option split was released in version 1.9.2 but %s is "
"installed. It will be ignored." % oml_version
)
operator.split = options["split"]
else:
operator.split = None
convert_lightgbm(scope, operator, container)
update_registered_converter(
LGBMRegressor,
"LightGbmLGBMRegressor",
calculate_linear_regressor_output_shapes,
skl2onnx_convert_lightgbm,
options={"split": None},
)
轉換¶
我們按照兩種情境轉換相同的模型,一種是單一 TreeEnsembleRegressor 節點,另一種則是多個節點。split 參數是每個 TreeEnsembleRegressor 節點的樹木數量。
model_onnx = to_onnx(
reg, X[:1].astype(numpy.float32), target_opset={"": 14, "ai.onnx.ml": 2}
)
model_onnx_split = to_onnx(
reg,
X[:1].astype(numpy.float32),
target_opset={"": 14, "ai.onnx.ml": 2},
options={"split": 100},
)
差異¶
sess = InferenceSession(
model_onnx.SerializeToString(), providers=["CPUExecutionProvider"]
)
sess_split = InferenceSession(
model_onnx_split.SerializeToString(), providers=["CPUExecutionProvider"]
)
X32 = X.astype(numpy.float32)
expected = reg.predict(X32)
got = sess.run(None, {"X": X32})[0].ravel()
got_split = sess_split.run(None, {"X": X32})[0].ravel()
disp = numpy.abs(got - expected).sum()
disp_split = numpy.abs(got_split - expected).sum()
print("sum of discrepancies 1 node", disp)
print("sum of discrepancies split node", disp_split, "ratio:", disp / disp_split)
sum of discrepancies 1 node 0.00020644343950206685
sum of discrepancies split node 4.144931004458315e-05 ratio: 4.980624268052108
差異總和減少了 4、5 倍。最大值也更好。
disc = numpy.abs(got - expected).max()
disc_split = numpy.abs(got_split - expected).max()
print("max discrepancies 1 node", disc)
print("max discrepancies split node", disc_split, "ratio:", disc / disc_split)
max discrepancies 1 node 1.985479140209634e-06
max discrepancies split node 2.6622454418756547e-07 ratio: 7.457911689805682
處理時間¶
處理時間較慢,但不會差太多。
print(
"processing time no split",
timeit.timeit(lambda: sess.run(None, {"X": X32})[0], number=150),
)
print(
"processing time split",
timeit.timeit(lambda: sess_split.run(None, {"X": X32})[0], number=150),
)
processing time no split 2.342391199999838
processing time split 2.7244762999998784
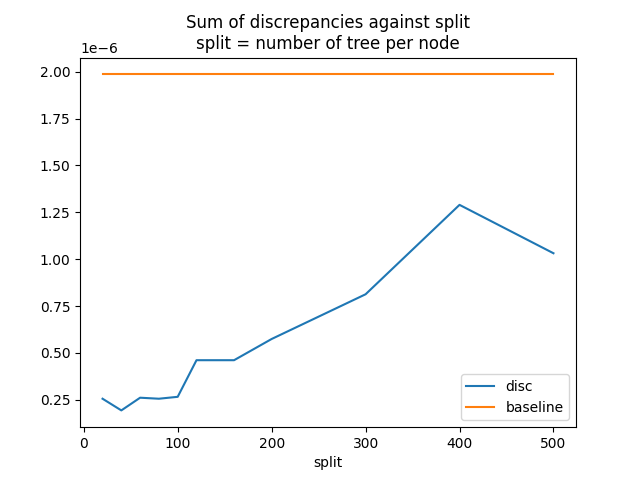
分割影響¶
讓我們看看差異總和如何針對參數 split 移動。
res = []
for i in tqdm(list(range(20, 170, 20)) + [200, 300, 400, 500]):
model_onnx_split = to_onnx(
reg,
X[:1].astype(numpy.float32),
target_opset={"": 14, "ai.onnx.ml": 2},
options={"split": i},
)
sess_split = InferenceSession(
model_onnx_split.SerializeToString(), providers=["CPUExecutionProvider"]
)
got_split = sess_split.run(None, {"X": X32})[0].ravel()
disc_split = numpy.abs(got_split - expected).max()
res.append(dict(split=i, disc=disc_split))
df = DataFrame(res).set_index("split")
df["baseline"] = disc
print(df)
0%| | 0/12 [00:00<?, ?it/s]
8%|▊ | 1/12 [00:01<00:17, 1.61s/it]
17%|█▋ | 2/12 [00:03<00:15, 1.51s/it]
25%|██▌ | 3/12 [00:04<00:13, 1.45s/it]
33%|███▎ | 4/12 [00:05<00:11, 1.43s/it]
42%|████▏ | 5/12 [00:07<00:09, 1.41s/it]
50%|█████ | 6/12 [00:08<00:08, 1.40s/it]
58%|█████▊ | 7/12 [00:10<00:07, 1.41s/it]
67%|██████▋ | 8/12 [00:11<00:05, 1.44s/it]
75%|███████▌ | 9/12 [00:12<00:04, 1.41s/it]
83%|████████▎ | 10/12 [00:15<00:03, 1.80s/it]
92%|█████████▏| 11/12 [00:17<00:01, 1.74s/it]
100%|██████████| 12/12 [00:18<00:00, 1.61s/it]
100%|██████████| 12/12 [00:18<00:00, 1.54s/it]
disc baseline
split
20 2.560464e-07 0.000002
40 1.937818e-07 0.000002
60 2.614565e-07 0.000002
80 2.560464e-07 0.000002
100 2.662245e-07 0.000002
120 4.614585e-07 0.000002
140 4.614585e-07 0.000002
160 4.614585e-07 0.000002
200 5.745647e-07 0.000002
300 8.129833e-07 0.000002
400 1.289820e-06 0.000002
500 1.031805e-06 0.000002
圖表。
指令碼總執行時間: (0 分鐘 27.317 秒)