轉換器¶
在生產環境中使用 ONNX 表示模型的預測函式可以使用 ONNX 運算子來實作。必須選擇一個在部署模型的平台上可用的執行階段。檢查差異,最後測量延遲。如果存在一個轉換程式庫,可支援模型的所有部分,則模型轉換的第一步可能會很簡單。如果不是這樣,則必須在 ONNX 中實作缺少的零件。這可能非常耗時。
什麼是轉換程式庫?¶
sklearn-onnx 將 scikit-learn 模型轉換為 ONNX。它使用上面介紹的 API,以 ONNX 運算子重寫模型的預測函式,無論它是什麼。它確保預測等於或至少非常接近使用原始模型計算的預期預測。
機器學習程式庫通常有自己的設計。這就是為什麼每個程式庫都有一個特定的轉換程式庫。其中許多列在這裡:轉換為 ONNX 格式。以下是一個簡短的列表
sklearn-onnx:轉換來自 scikit-learn 的模型,
tensorflow-onnx:轉換來自 tensorflow 的模型,
onnxmltools:轉換來自 lightgbm、xgboost、pyspark、libsvm 的模型
torch.onnx:轉換來自 pytorch 的模型。
所有這些程式庫的主要挑戰是跟上進度。它們必須在每次 ONNX 或它們支援的程式庫發佈新版本時進行更新。這意味著每年有三到五個新版本。
轉換程式庫彼此不相容。tensorflow-onnx 專用於 tensorflow,僅限 tensorflow。sklearn-onnx 專門用於 scikit-learn,也是如此。
一個挑戰是客製化。很難支援機器學習模型中的自訂部分。它們必須為這個部分編寫特定的轉換器。在某種程度上,這就像實作兩次預測函式。有一個簡單的案例:深度學習架構有自己的基本元素,以確保相同的程式碼可以在不同的環境中執行。只要自訂層或子部分使用 pytorch 或 tensorflow 的部分,就不需要做太多事情。對於 scikit-learn 來說,情況就不同了。這個套件沒有自己的加法或乘法,它依賴 numpy 或 scipy。使用者必須使用 ONNX 基本元素來實作其轉換器或預測器,無論它是否使用 numpy 實作。
替代方案¶
實作 ONNX 匯出功能的一種替代方案是利用標準協定,例如 Array API 標準,該標準將一組常見的陣列操作標準化。它可以跨 NumPy、JAX、PyTorch、CuPy 等程式庫重複使用程式碼。ndonnx 透過 ONNX 後端啟用執行,並為符合 Array API 的程式碼提供即時 ONNX 匯出。由於用於實作大多數程式庫的相同程式碼可以在 ONNX 轉換中重複使用,因此減少了對專用轉換器程式庫程式碼的需求。它還為希望在建構 ONNX 圖形時獲得類似 NumPy 體驗的轉換器作者提供了一個方便的基本元素。
運算子集¶
ONNX 發佈的版本具有版本號,例如 major.minor.fix。每個次要更新表示運算子的清單不同或簽名已變更。它也與一個運算子集相關聯,版本 1.10 是運算子集 15,1.11 將是運算子集 16。每個 ONNX 圖形都應定義它遵循的運算子集。在不更新運算子的情況下變更此版本可能會使圖形無效。如果運算子集保持未指定,則 ONNX 將認為圖形對最新的運算子集有效。
新的運算子集通常會引入新的運算子。可以以不同的方式實作相同的推論函式,通常以更有效率的方式。但是,模型執行的執行階段可能不支援最新的運算子集,或者至少在已安裝的版本中不支援。這就是為什麼每個轉換程式庫都提供為特定運算子集建立 ONNX 圖形的可能性,通常稱為 target_opset。ONNX 語言描述簡單和複雜的運算子。變更運算子集類似於升級程式庫。onnx 和 onnx 執行階段必須支援向後相容性。
其他 API¶
先前章節中的範例顯示 onnx API 非常冗長。除非圖形很小,否則也很難通過閱讀程式碼來獲得圖形的整體概觀。幾乎每個轉換程式庫都實作了不同的 API 來建立圖形,通常比 onnx 套件的 API 更簡單、更簡潔。所有 API 自動化了初始值設定項的添加、隱藏每個中間結果名稱的建立,並處理不同運算子集的不同版本。
具有 add_node 方法的 Graph 類別¶
tensorflow-onnx 實作了一個圖形類別。當 ONNX 沒有類似的函式時,它會用 ONNX 運算子重寫 tensorflow 函式(請參閱 Erf)。
sklearn-onnx 定義了兩種不同的 API。在該範例 實作轉換器 中介紹的第一個遵循與 tensorflow-onnx 類似的設計。以下幾行是從線性分類器的轉換器中提取的。
# initializer
coef = scope.get_unique_variable_name('coef')
model_coef = np.array(
classifier_attrs['coefficients'], dtype=np.float64)
model_coef = model_coef.reshape((number_of_classes, -1)).T
container.add_initializer(
coef, proto_dtype, model_coef.shape, model_coef.ravel().tolist())
intercept = scope.get_unique_variable_name('intercept')
model_intercept = np.array(
classifier_attrs['intercepts'], dtype=np.float64)
model_intercept = model_intercept.reshape((number_of_classes, -1)).T
container.add_initializer(
intercept, proto_dtype, model_intercept.shape,
model_intercept.ravel().tolist())
# add nodes
multiplied = scope.get_unique_variable_name('multiplied')
container.add_node(
'MatMul', [operator.inputs[0].full_name, coef], multiplied,
name=scope.get_unique_operator_name('MatMul'))
# [...]
argmax_output_name = scope.get_unique_variable_name('label')
container.add_node('ArgMax', raw_score_name, argmax_output_name,
name=scope.get_unique_operator_name('ArgMax'),
axis=1)
將運算子作為函式¶
在實作新的轉換器中展示的第二個 API 更為精簡,並將每個 ONNX 運算子定義為可組合的函式。對於 KMeans 來說,語法如下,更簡潔且易於閱讀。
rs = OnnxReduceSumSquare(
input_name, axes=[1], keepdims=1, op_version=opv)
gemm_out = OnnxMatMul(
input_name, (C.T * (-2)).astype(dtype), op_version=opv)
z = OnnxAdd(rs, gemm_out, op_version=opv)
y2 = OnnxAdd(C2, z, op_version=opv)
ll = OnnxArgMin(y2, axis=1, keepdims=0, output_names=out[:1],
op_version=opv)
y2s = OnnxSqrt(y2, output_names=out[1:], op_version=opv)
從經驗中學習到的技巧¶
差異¶
ONNX 是強型別的,並針對 float32 進行最佳化,這是深度學習中最常見的型別。標準機器學習中的函式庫同時使用 float32 和 float64。numpy 通常會轉換為最通用的型別 float64。當預測函式是連續的時候,這沒有顯著的影響。當它不是連續的時候,必須使用正確的型別。範例 切換為 float 時的問題 提供了更多關於該主題的深入見解。
平行化會改變計算的順序。這通常不顯著,但它可能解釋一些奇怪的差異。 1 + 1e17 - 1e17 = 0 但是 1e17 - 1e17 + 1 = 1。高數量級的數字很少見,但當模型使用矩陣的逆矩陣時,也不是那麼罕見。
IsolationForest 技巧¶
ONNX 只實作了 TreeEnsembleRegressor,但它沒有提供檢索決策所遵循的路徑或圖表統計資訊的可能性。技巧是使用一個森林來預測葉節點的索引,並將此葉節點索引對應一次或多次到所需資訊。
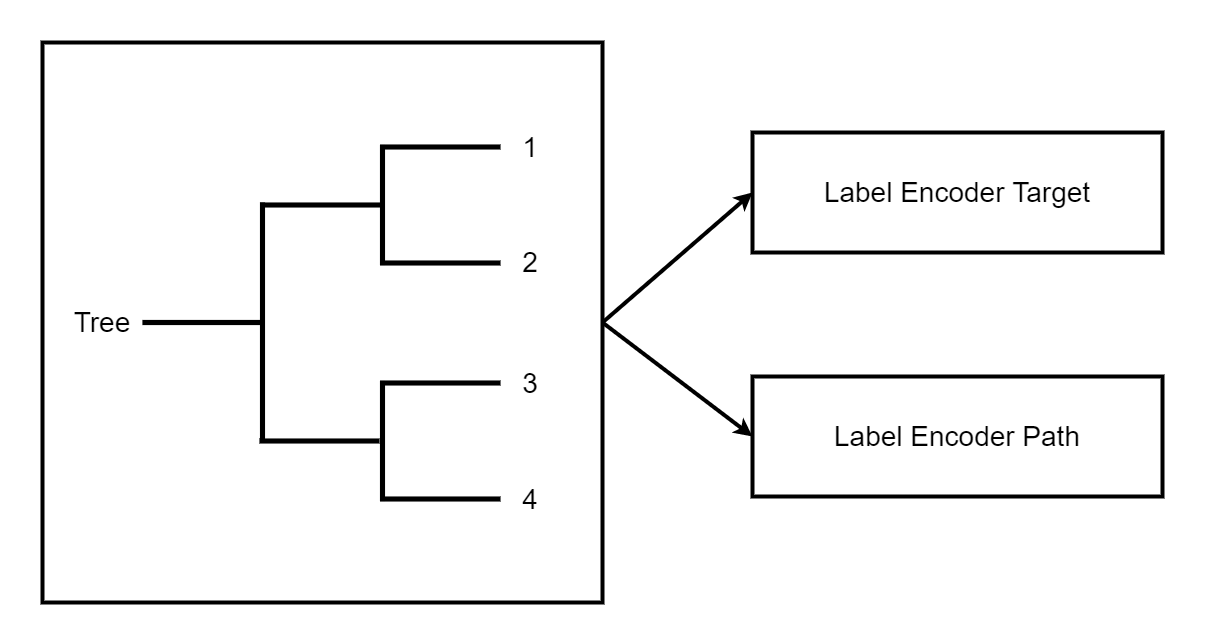
離散化¶
查找特徵落入哪個區間。這很容易用 numpy 來完成,但是用 ONNX 高效地完成並不容易。最快的方法是使用 TreeEnsembleRegressor,一種二元搜尋,它會輸出區間索引。這就是此範例實作的內容:WOE 轉換器的轉換器。
貢獻¶
onnx 儲存庫 必須被 fork 和 clone。
建置¶
Windows 建置需要 conda。以下步驟可能不是最新的。資料夾 onnx/.github/workflows 包含最新的說明。
Windows
使用 Anaconda 建置更為容易。首先:建立一個環境。這必須只做一次。
conda create --yes --quiet --name py3.9 python=3.9
conda install -n py3.9 -y -c conda-forge numpy libprotobuf=3.16.0
然後建置套件
git submodule update --init --recursive
set ONNX_BUILD_TESTS=1
set ONNX_ML=$(onnx_ml)
set CMAKE_ARGS=-DONNX_USE_PROTOBUF_SHARED_LIBS=ON -DONNX_USE_LITE_PROTO=ON -DONNX_WERROR=ON
python -m build --wheel
現在可以安裝套件了。
Linux
在 clone 儲存庫後,可以執行以下指令
python -m build --wheel
建置 markdown 文件¶
必須先建置套件 (參見上一節)。
set ONNX_BUILD_TESTS=1
set ONNX_ML=$(onnx_ml)
set CMAKE_ARGS=-DONNX_USE_PROTOBUF_SHARED_LIBS=ON -DONNX_USE_LITE_PROTO=ON -DONNX_WERROR=ON
python onnx\gen_proto.py -l
python onnx\gen_proto.py -l --ml
pip install -e .
python onnx\backend\test\cmd_tools.py generate-data
python onnx\backend\test\stat_coverage.py
python onnx\defs\gen_doc.py
set ONNX_ML=0
python onnx\defs\gen_doc.py
set ONNX_ML=1
更新現有的運算子¶
所有運算子都在資料夾 onnx/onnx/defs 中定義。每個子資料夾中有兩個檔案,一個稱為 defs.cc,另一個稱為 old.cc。
defs.cc:包含每個運算子的最新定義old.cc:包含先前運算集中的運算子已棄用的版本
更新運算子意味著將定義從 defs.cc 複製到 old.cc,並更新 defs.cc 中的現有運算子。
必須修改一個遵循 onnx/defs/operator_sets*.h 模式的檔案。這些標頭會註冊現有運算子的清單。
檔案 onnx/defs/schema.h 包含最新的運算集版本。如果升級了一個運算集,也必須更新此檔案。
檔案 onnx/version_converter/convert.h 包含在將節點從一個運算集轉換到下一個運算集時要套用的規則。此檔案也可能會更新。
必須編譯套件並再次產生文件,以自動更新 markdown 文件,並且必須將其包含在 PR 中。
然後必須更新單元測試。
總結
修改檔案
defs.cc、old.cc、onnx/defs/operator_sets*.h、onnx/defs/schema.h選用:修改檔案
onnx/version_converter/convert.h建置 onnx。
建置文件。
更新單元測試。
PR 應包含修改過的檔案和修改過的 markdown 文件,通常是 docs/docs/Changelog-ml.md、docs/Changelog.md、docs/Operators-ml.md、docs/Operators.md、docs/TestCoverage-ml.md、docs/TestCoverage.md 的子集。